在 Day6 的時候我們提到當context length越長,KV cache也會越大,分配KV cache也成為一個挑戰的工作 🧠。在 Day12 學習到最原始的方法通常是根據每個request最大的長度去提前分配儲存空間,但如果request生成回應較短,會造成儲存資源的浪費 🗃️💔。
最早有研究提出預測每個request生成的長度上限,來減少空間分配的浪費。然而,當不存在這麼大的連續空間時,靜態KV快取記憶體分配方式仍會失敗。
問題在連續空間的使用,OK,那就不要連續空間就好了啊! ✨

(圖源:自製,找不到把前面兩個人丟下去的版本QQ)
而PagedAttention被提出來解決這個問題,它跟傳統的attention演算法有些不同,它允許在不連續的記憶體空間中儲存連續的key和value,是一種有效率地在記憶體上管理KV cache的方法 🗂️。這是vLLM提出的方法,靈感來自傳統作業系統的概念,分頁 (paging) 📑 和 虛擬記憶體 (virtual memory) 💾。
至於這兩個是什麼呢?先理解完之後會對PagedAttention的方法更有概念。
虛擬記憶體
分頁
Paging是實現虛擬記憶體的一種技術,簡單來說就是當程式運作時,電腦只會用到一部分的page,其他的可以暫時放到硬碟上。它的過程如下:
首先將虛擬記憶體切成一小塊一小塊的page,而實體記憶體 (RAM)則劃分為對應的page frame。當作業系統需要將某段虛擬記憶體映射到RAM時,它會按照page的單位進行分配。
當一個程式需要使用某個虛擬記憶體的地址,作業系統會通過查找「page table」來將該虛擬記憶體的page映射到對應的frame。
當RAM不足時,作業系統可以將某些暫時不用的page從RAM中移到硬碟上的「交換區 (swap space)」,而當需要這些page時,再將它們讀回RAM,這個過程稱為「Page Swapping」。
如果想看更詳細的介紹和圖片,witscad的這篇圖片很好懂。
看完虛擬記憶體的方法之後,各位是否能猜出PagedAttention的運作原理了呢?
沒錯,就是一樣的概念!只是記憶體放的不是運作的程式,而是attention計算後的KV cache!而同理,RAM換成是VRAM,bytes換成是tokens,pages換成是blocks,page table換成是block table,processes換成是sequences。唯一的差別是作業系統主要針對所有的RAM,但PagedAttention可以是自行分配的一段VRAM。
🔍 簡單對照一下:
RAM --------------> VRAM
bytes -------------> tokens
pages ------------> blocks
page table ------> block table
processes -------> sequences
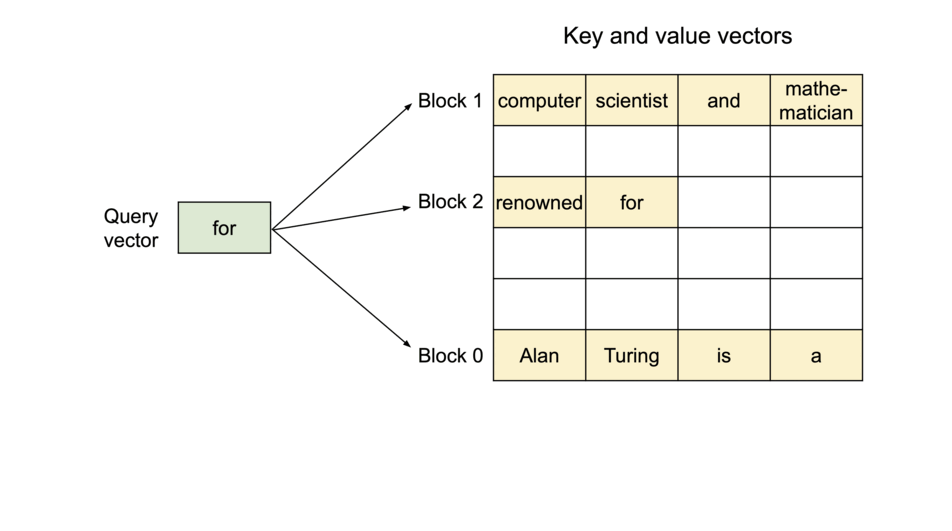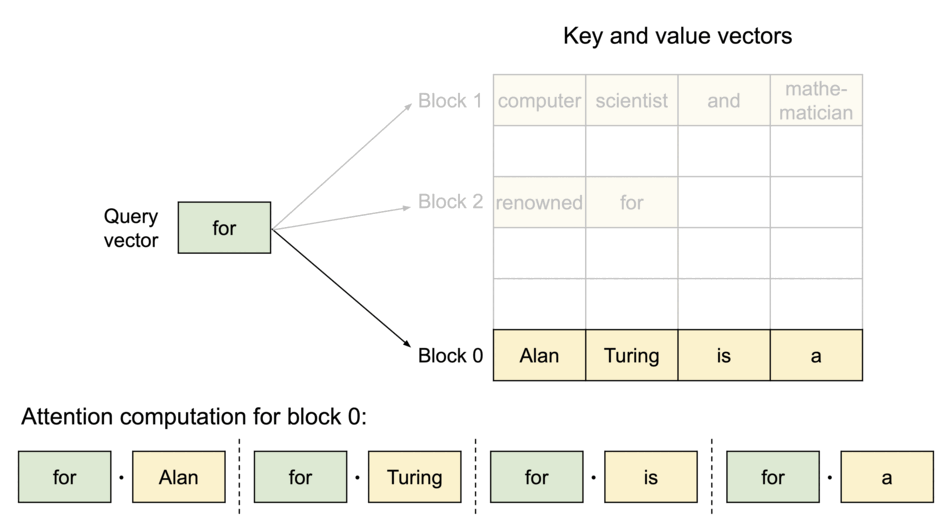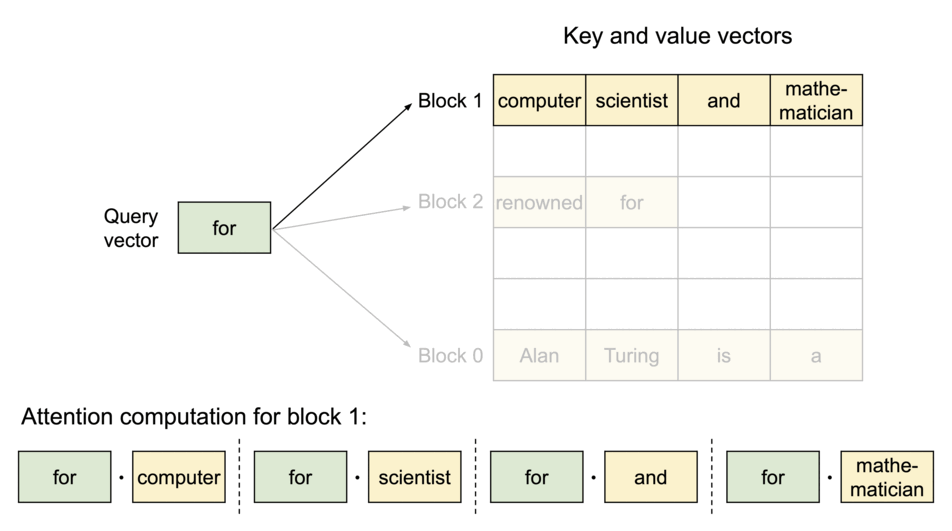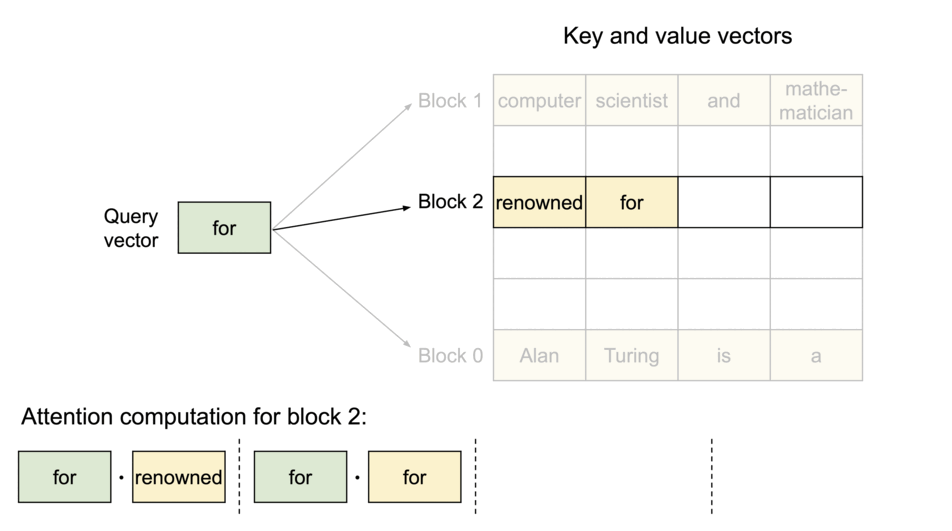
(圖源: vLLM blog,KV Cache被分割為logical blocks)
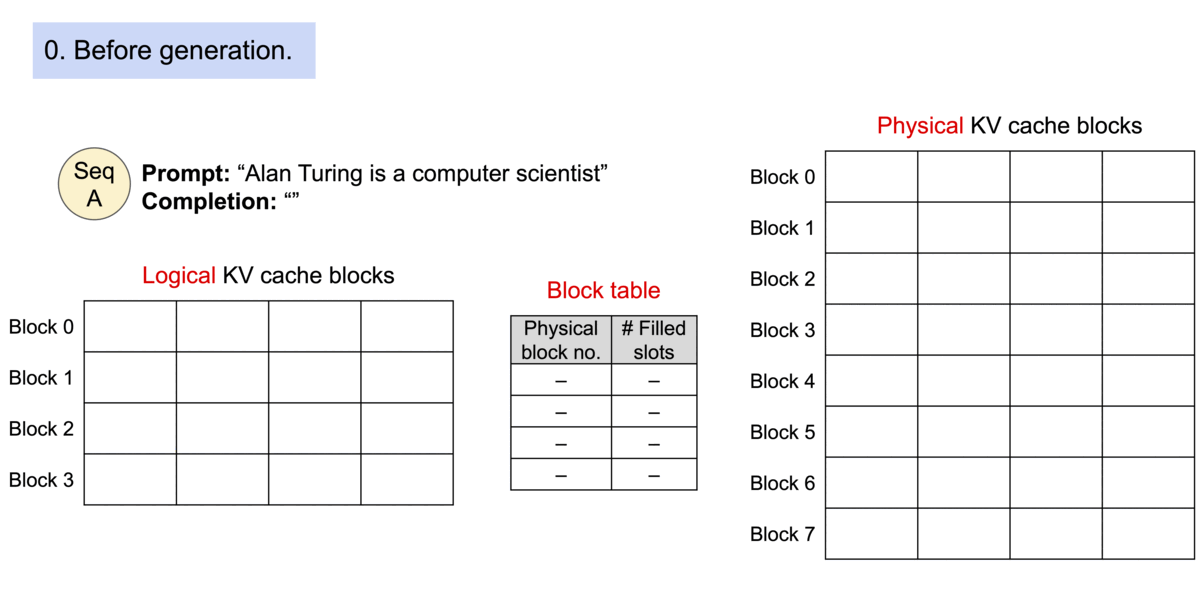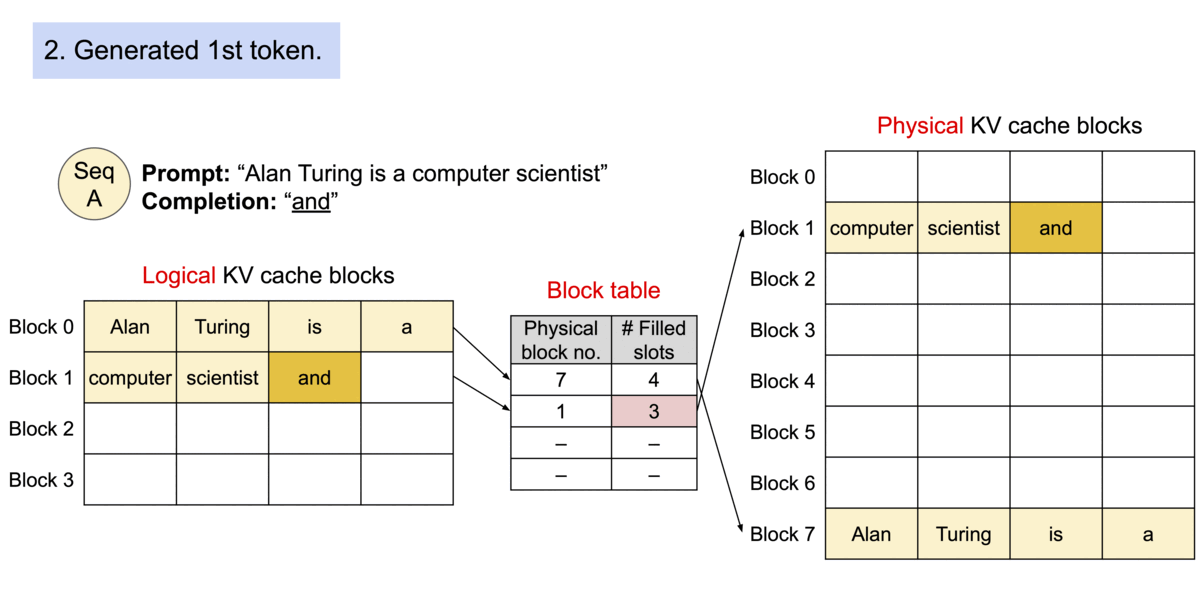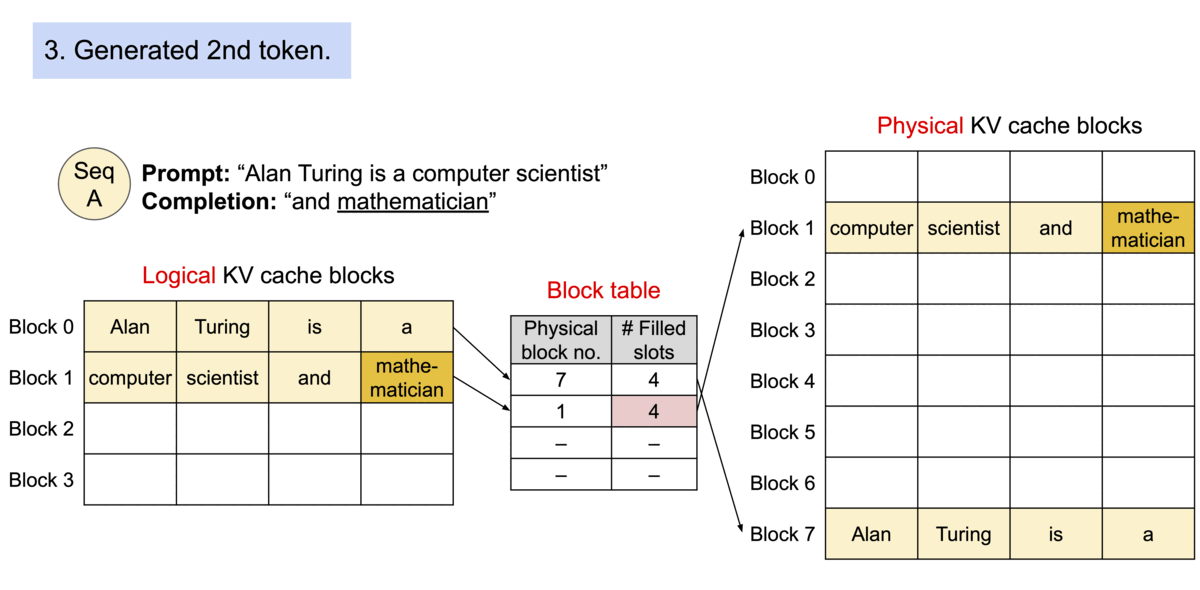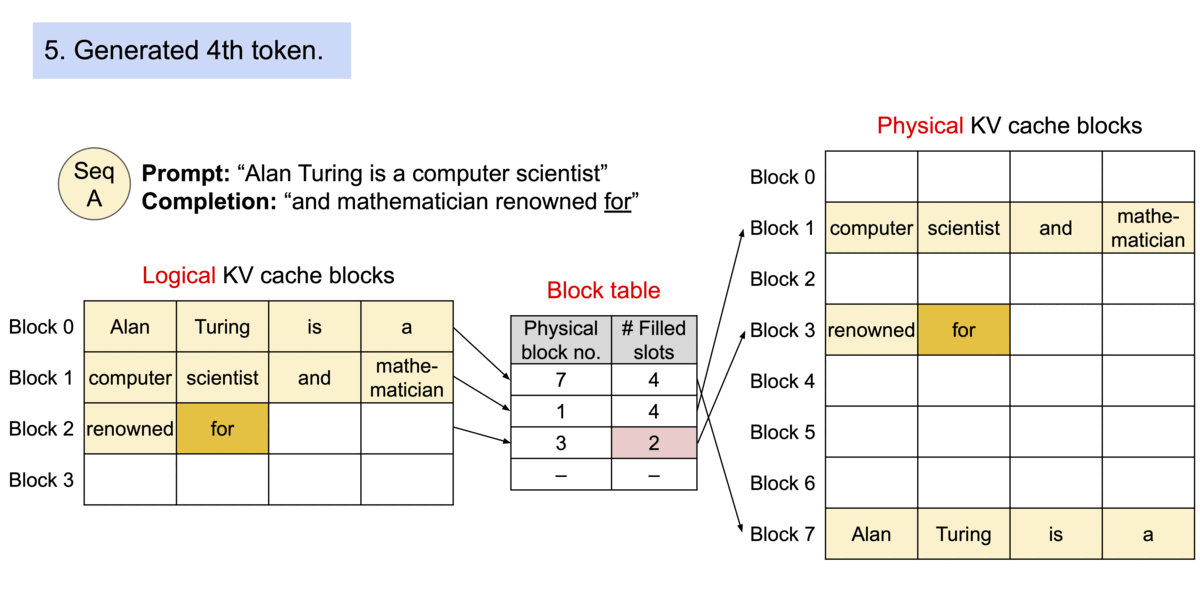
(圖源: vLLM blog,使用PagedAttention的過程)
因此在PagedAttention中,記憶體浪費只發生在序列的最後一個區塊中,已經很接近最完美的使用了,整體的浪費率變成低於4%。它允許系統將更多序列一起做batching,再更加提高GPU使用率和吞吐量,可以更完美的壓榨GPU了!
另外blog還提到了PagedAttention記憶體共享的優點,降低了複雜採樣演算法 (如 parallel sampling 和 beam search) 的記憶體花費,來加快運行速度和節省資源。
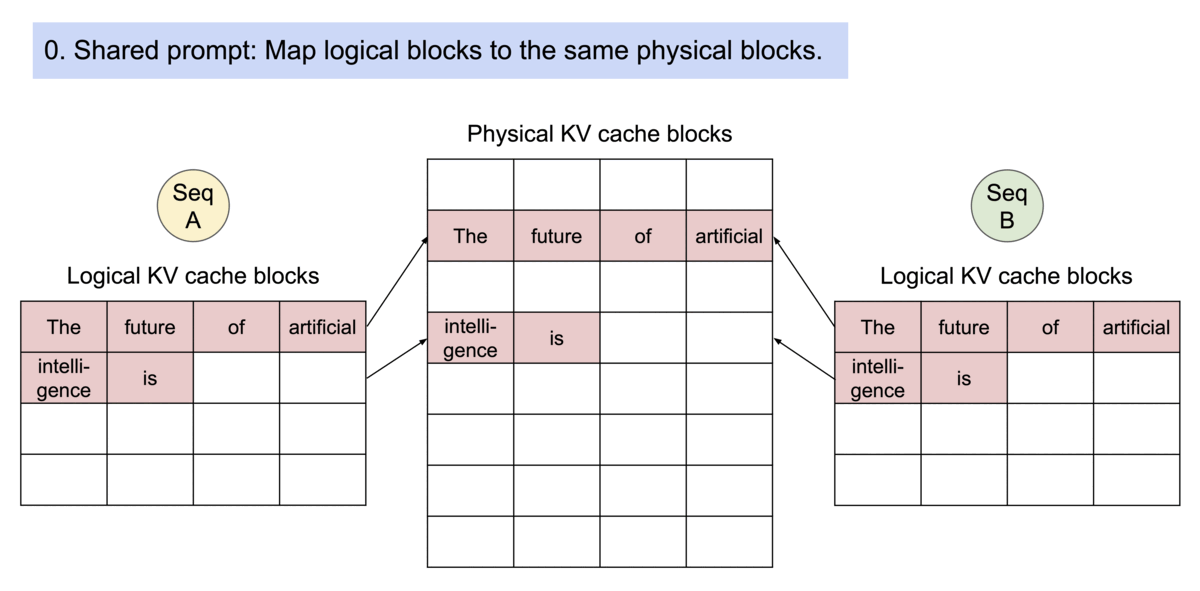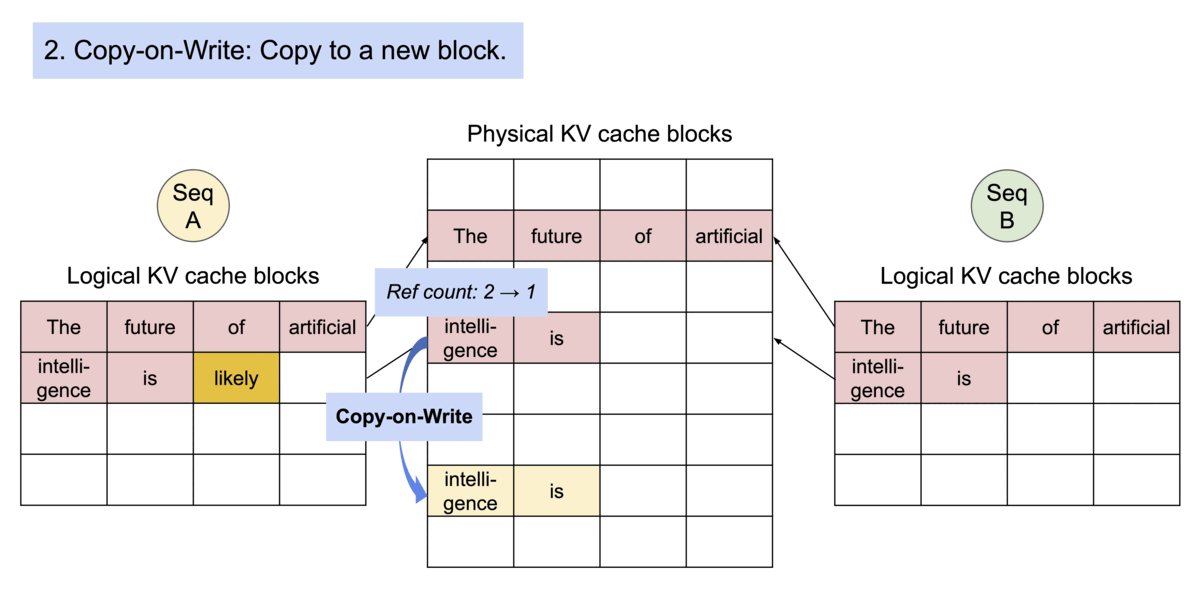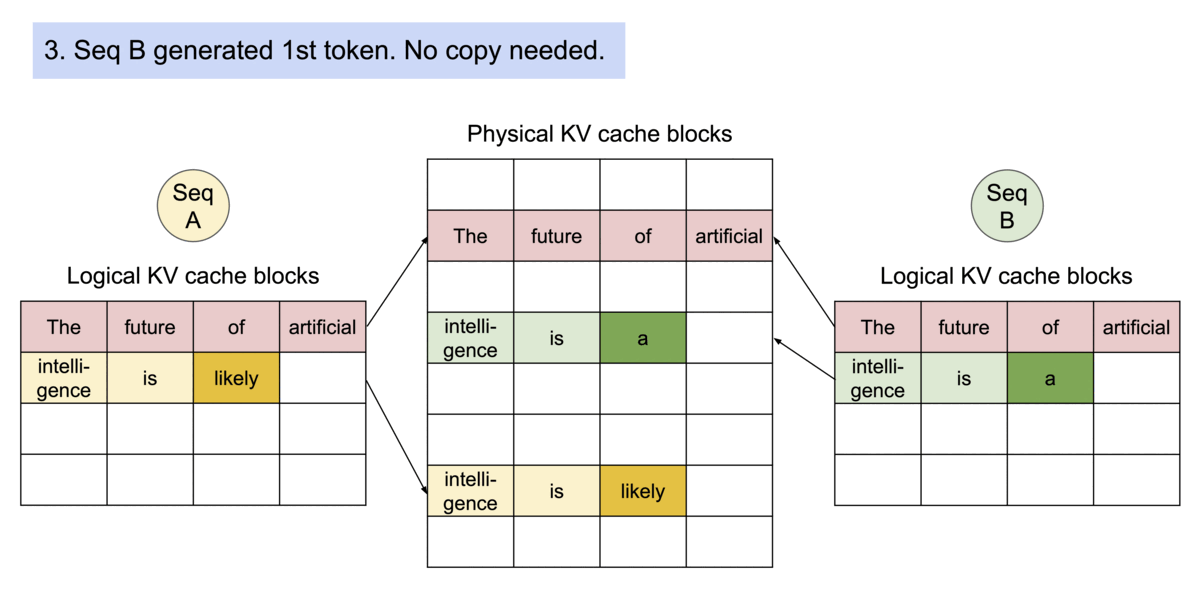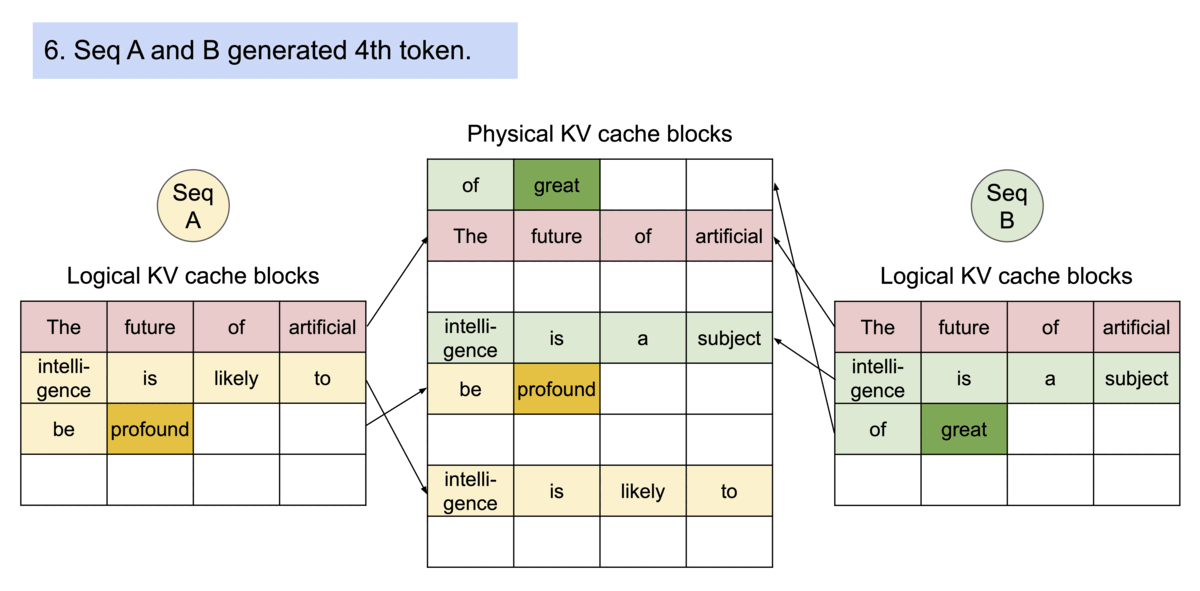
以parallel sampling為例,需要從同一個prompt生成多個輸出序列,PagedAttention就可以讓這些輸出「共用」之前的計算結果和記憶體空間。
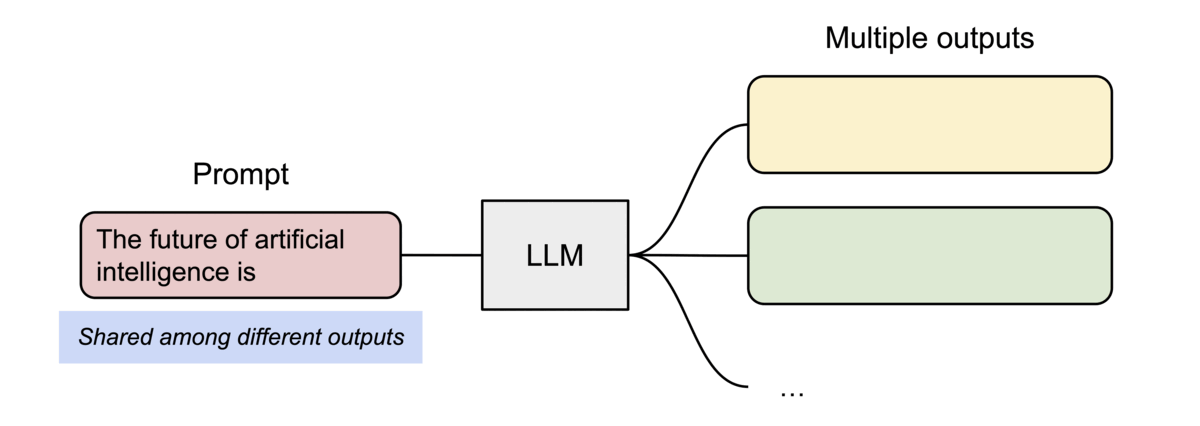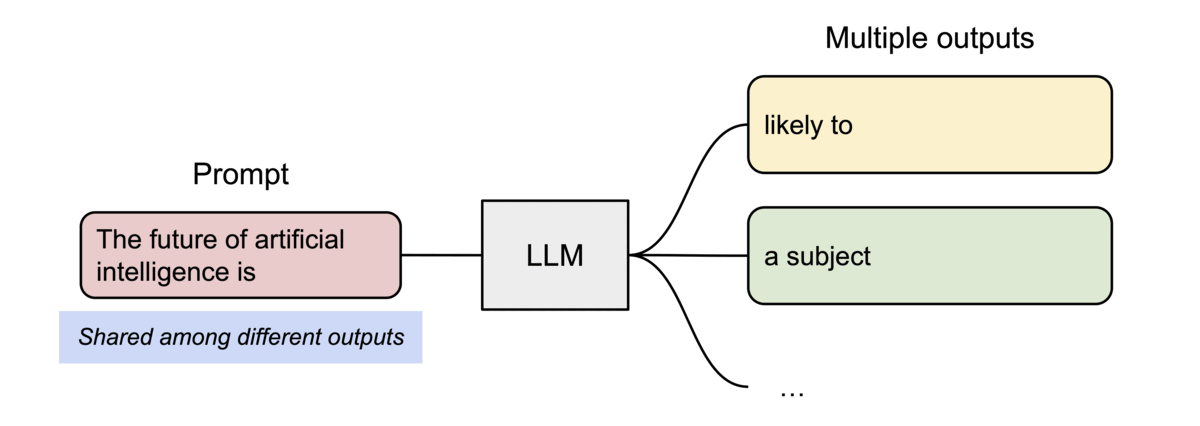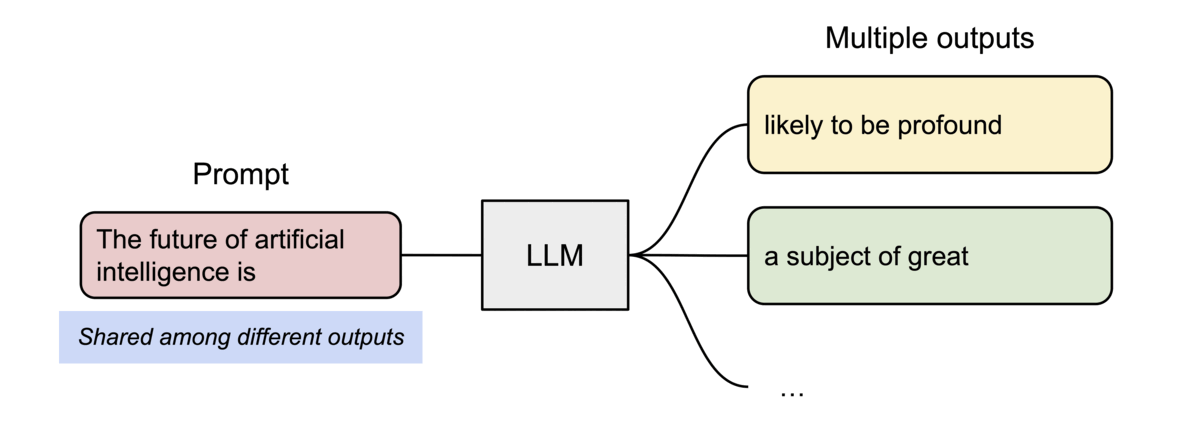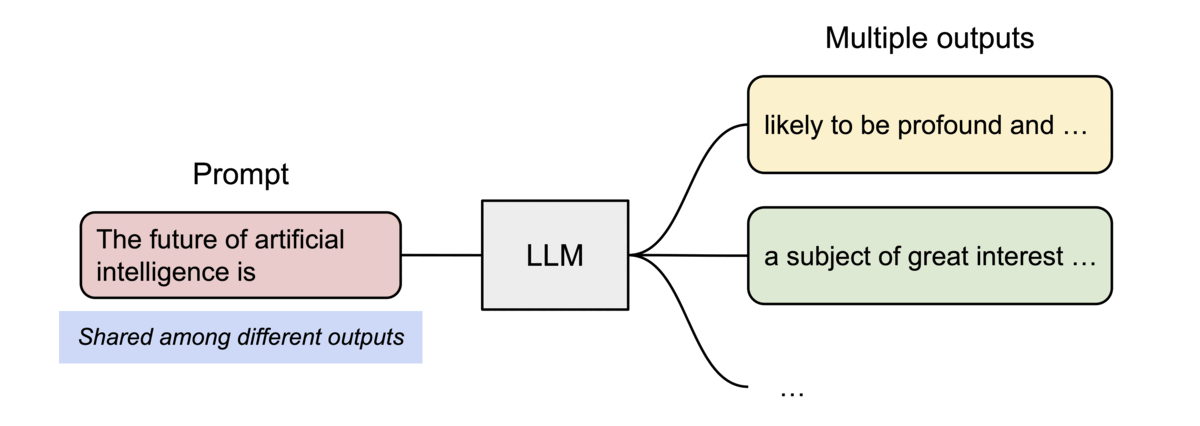
(圖源: vLLM blog,parallel sampling的範例圖)
它的原理也很簡單,因為有了block table,可以將不同序列的logical KV cache blocks映射到相同的physical KV cache blocks上。
為了不要讓這資料還在使用中就被刪除了,PagedAttention持續紀錄physical blocks的「引用次數 (reference counts)」,記住這個資料有多少序列正在使用,這樣當不再需要這個資料時,PagedAttention就可以知道是否該把這個資料清除。
另外,如果其中有一個輸出想要更改這份資料,那其他共用中的序列怎麼辦?
PagedAttention的「Copy-on-Write 機制」是「在需要寫入新資料時才複製」。這樣做的好處是,如果資料沒有被修改,就不會浪費資源複製它,只有在真的需要修改時,才會複製出一份新的來給需要修改的序列使用,如下圖。
(圖源: vLLM blog,reference counts和Copy-on-Write)
整體而言,PageAttention可以將其記憶體佔用降低55%,還將吞吐量提高2.2倍,實在是太神啦。
這一章介紹了PageAttention是怎麼應用作業系統中虛擬記憶體概念,變成適合運作的LLM版本,原理其實很簡單 💡,它除了可以減少GPU在等待VRAM讀取時的閒置時間 🕒,來提高GPU使用率、增加吞吐量之外,還可以讓一些原本需要消耗大量記憶體的演算法也可以被成功執行,甚至能夠更好地處理長序列時會遇到記憶體瓶頸,整體而言減少了大大的成本開銷 💰。
🔍 最後簡單整理一下它的優點:
- 提高GPU使用率 📈
- 增加吞吐量 📊
- 執行複雜演算法 🛠️
- 處理長序列記憶體問題 🔄
P.S. 為了讓技術文章不要那麼難閱讀,隊友筆建議筆者將Day10之後的文章都放滿表情符號(^∀^●)ノシ(^∀^●)ノシ(^∀^●)ノシ
How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
https://www.anyscale.com/blog/continuous-batching-llm-inference
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
https://blog.vllm.ai/2023/06/20/vllm.html

